OverviewPiccolo was developed using the parser generator tools JFlex
and BYACC/J. The bulk of the Piccolo source code is in
Piccolo.y and PiccoloLexer.flex, which are compiled
to create Piccolo.java and PiccoloLexer.java, respectively.
Traditionally, Flex is used to scan input into lexical tokens
which are passed to the grammar-parsing code built with YACC (Yet
Another Compiler Compiler). In Piccolo, most of the parsing code
is actually in the Flex file. YACC is used primarily to parse
the DTD. If you are not already familiar with JFlex and BYACC/J,
you should read their documentation before diving into Piccolo's
source code.
Building Piccolo
You'll need to download the Piccolo source code, modified JFlex,
modified BYACC/J, and Ant. BYACC/J is written in C and I've only
included the Windows executable. If you have another platform,
you'll need a C compiler too. Whew! Once you've got all that,
you can just type "ant" to make the magic happen.
Application Flow
Piccolo.java is the entry point. It implements the SAX
interfaces and does the initialization such as creating an XMLStreamReader
to read the input in the proper character encoding. Piccolo's
driver loop repeatedly calls PiccoloLexer.yylex() to scan
the text and return tokens. When the DTD has been parsed and the
root-level element has been read, PiccoloLexer is put into
"direct mode" and takes over almost all the parsing
and SAX callbacks. When the closing root-level element has been
read, Piccolo finishes the job.
Parser Generators vs. Hand coding
One of the nice things about parser generators is that efficient
parsers for complex syntax can be written with easily understood
"rules." In the "C" world, parsers using the
lex and yacc parser generators were often much faster
than traditionally written parsers, because state transitions
were calculated with array lookups.
Arrays in "C" are very fast, but in Java there is some
overhead for each array lookup. For that reason, small switch
statements which do not use arrays can sometimes be faster than
JFlex's generic driver loop.
For these performance reasons, some of Piccolo's XML parsing
is done not through JFlex rules but "by hand." Parsing
complex constructs such as DTDs is very fast using JFlex rules,
but XML element content is simple enough that switch
statements can be crafted to optimize performance over JFlex.
Token passing between PiccoloLexer and Piccolo is also avoided
wherever feasible, because this interaction has some overhead
and much of XML parsing is simple enough to do entirely within
the lexer.
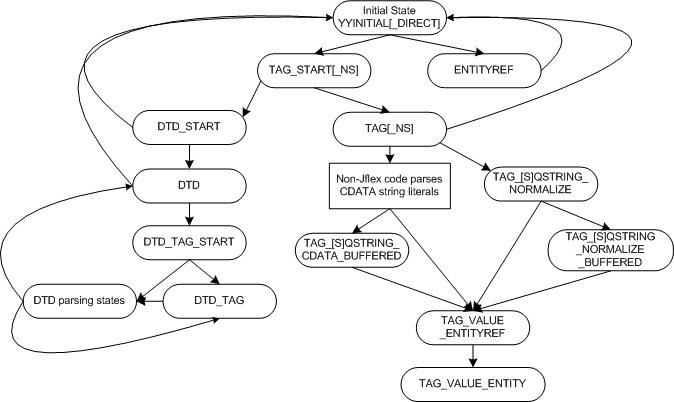
PiccoloLexer State Transitions
In order to implement parsing functionality within JFlex rules,
additional variables are used to combine similar states and to
facilitate state transitions. The prevState variable is
used to save the current state so that we can enter another state
and then return. This provides subroutine-like functionality,
used to enter and exit states used to parse constructs such as
entity references which can appear in many contexts.
Below is an overview of the major state transitions in PiccoloLexer.
Javadoc
The documentation generated by the
javadoc utility can give you a quick look at the supporting
Java classes.
|